|
|
|
|
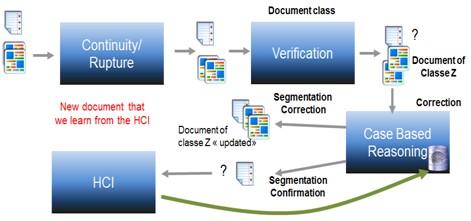
| This software is designed by Hani Daher during his postdoctoral period, between 2012 and 2014. The model links two incremental classification modules. The first creates two classes, one representing the continuity, another the rupture. The input vectors are the result of comparison of factual descriptor vectors in two successive pages. In case of rupture shown on a pair of pages, the second page becomes the beginning of a new document. The second classifier classifies documents from a bag of words. He just confirm or deny the segmentation made ??by his predecessor. The latter classification is also used for a correction module of a case based reasoning type that will correct any registered error. segmentation |
|
|
|
| Each page is recognized by OCR and the result is an XML file. From this file are extracted textual descriptors such as dates, phone numbers, numeric and alphanumeric codes, etc. These descriptors are compared in pairs of consecutive pages in the stream and a descriptor vector is formed. For each descriptor observed in two pages, 3 values are performed showing its degree in continuity, rupture or uncertainty. |

|
|
|
|
The algorithm of the proposed method constructs and maintains a model in the form of a graph G whose nodes are representatives of documents.
Each node of G is a vector of characteristics that is updated continuously by the algorithm.
The algorithm 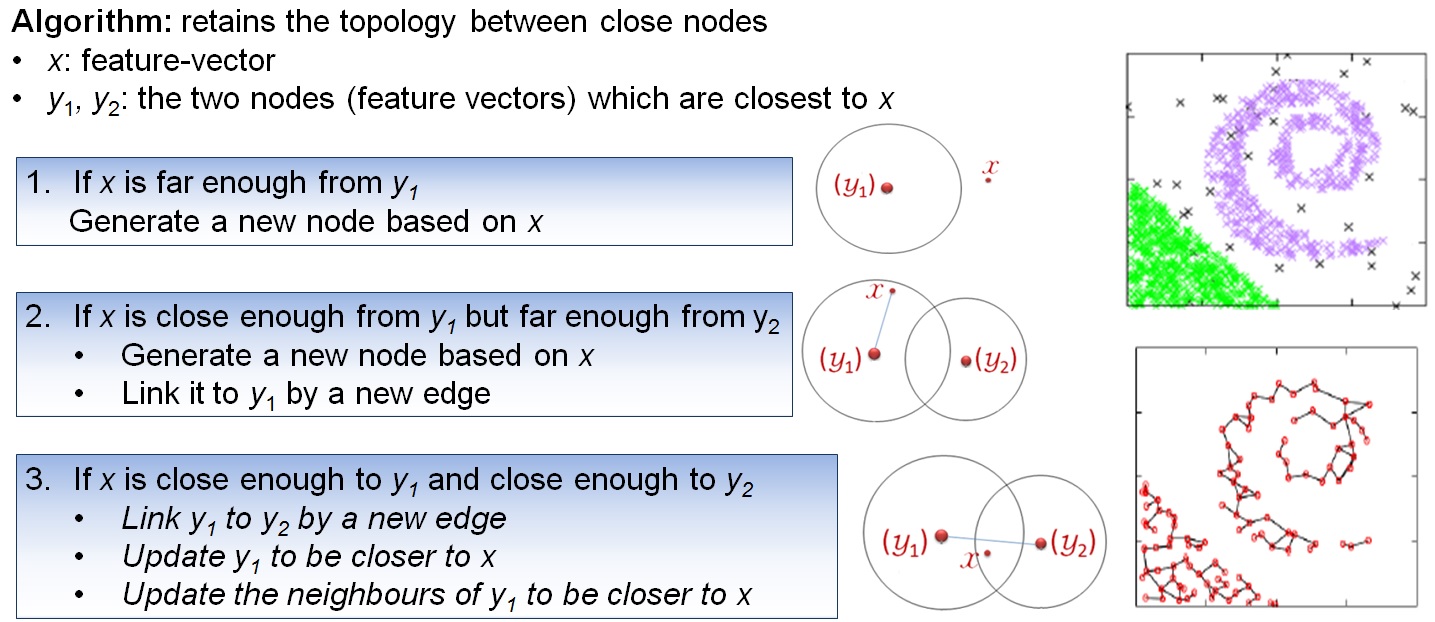 Rejection  |
|
|
| Databases
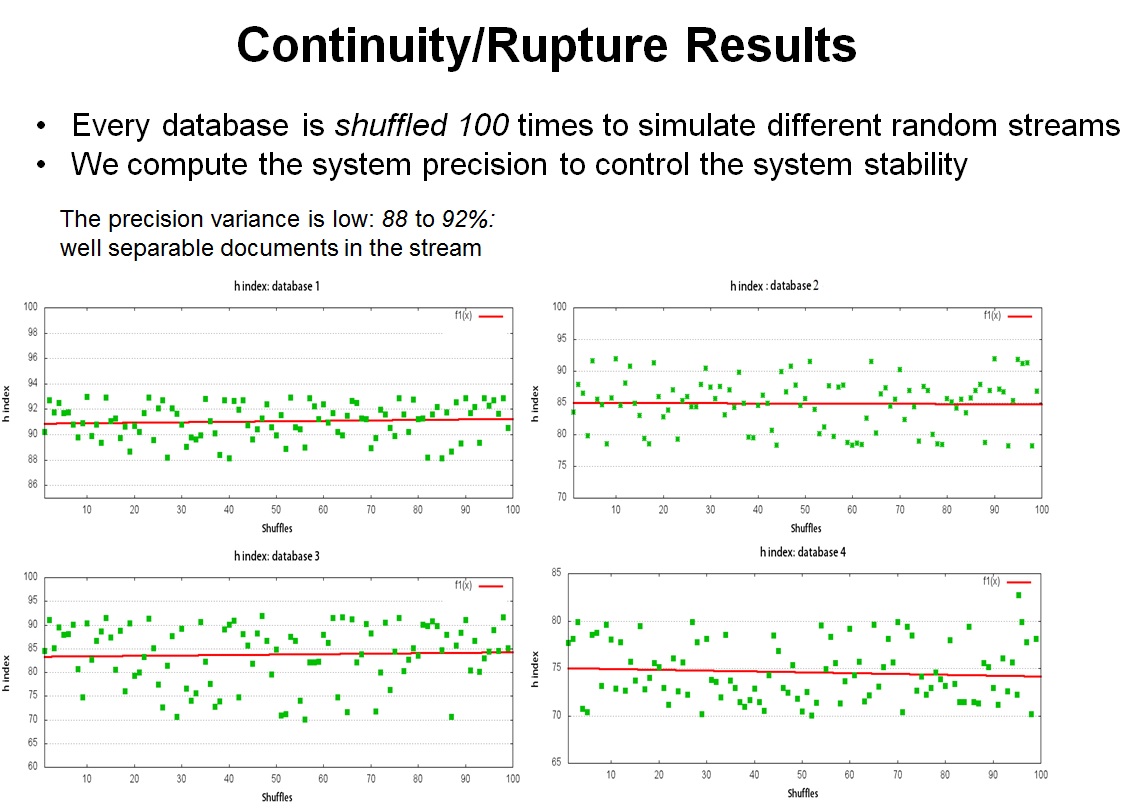
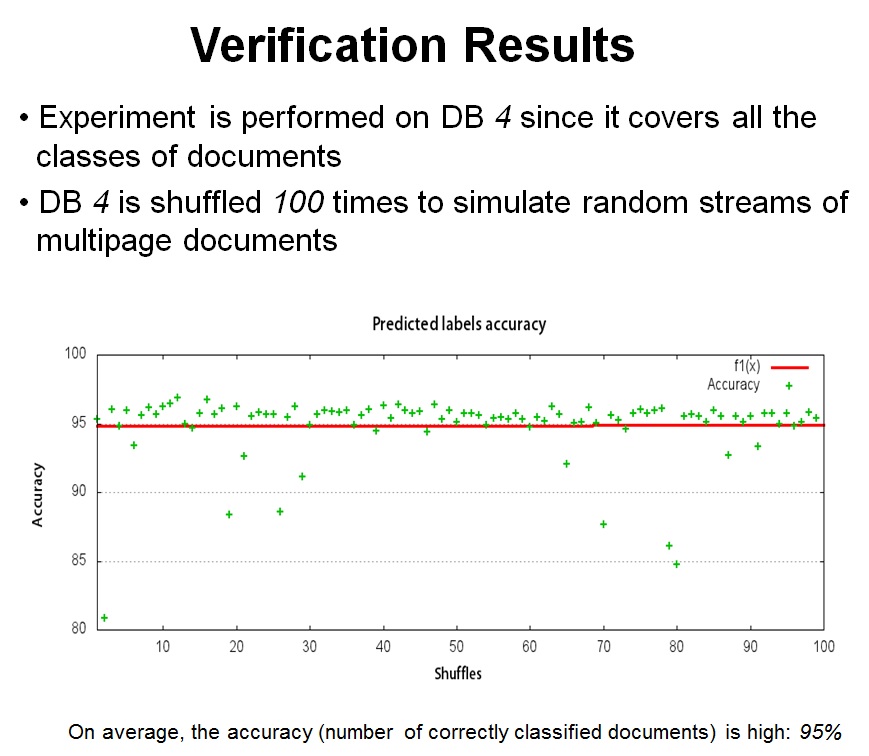
4 databases have been constituted:
|
 |
 |
 |
|
|
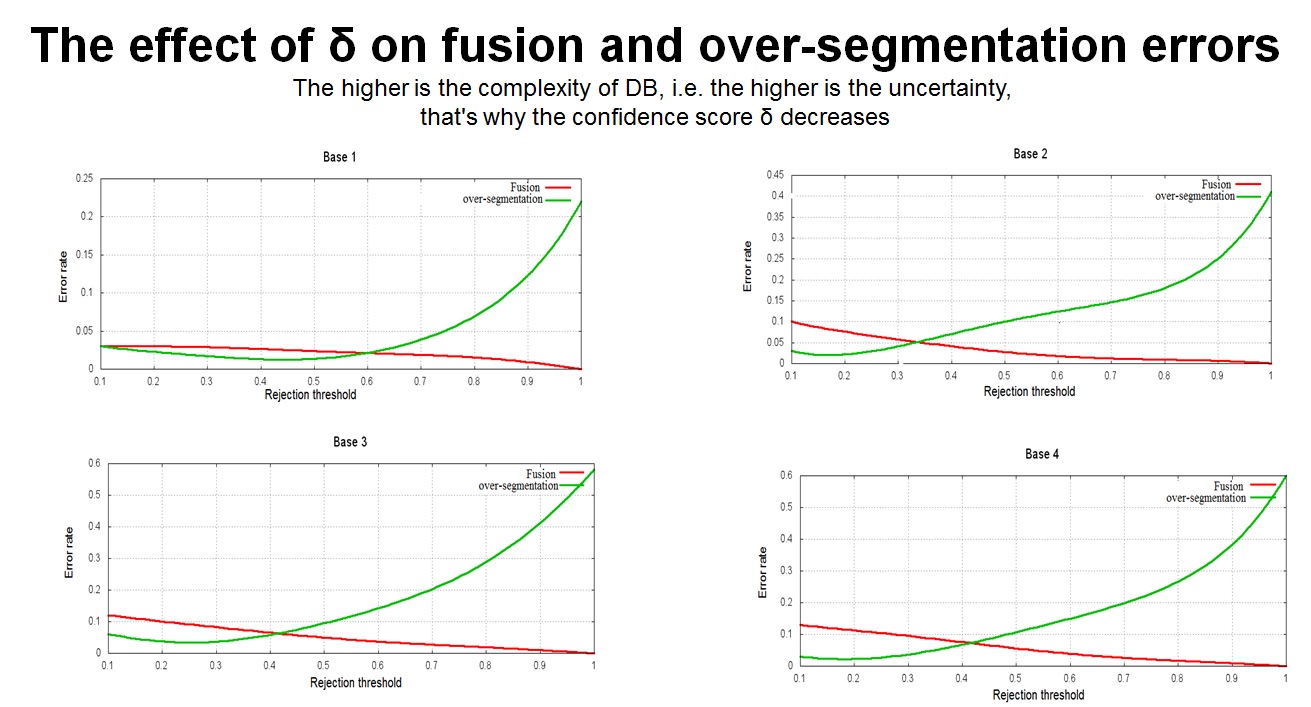
| Figure 1
The self-test function allows variations in the rejection thresholds in the learning flow. We get a curve plotting the various scores
|
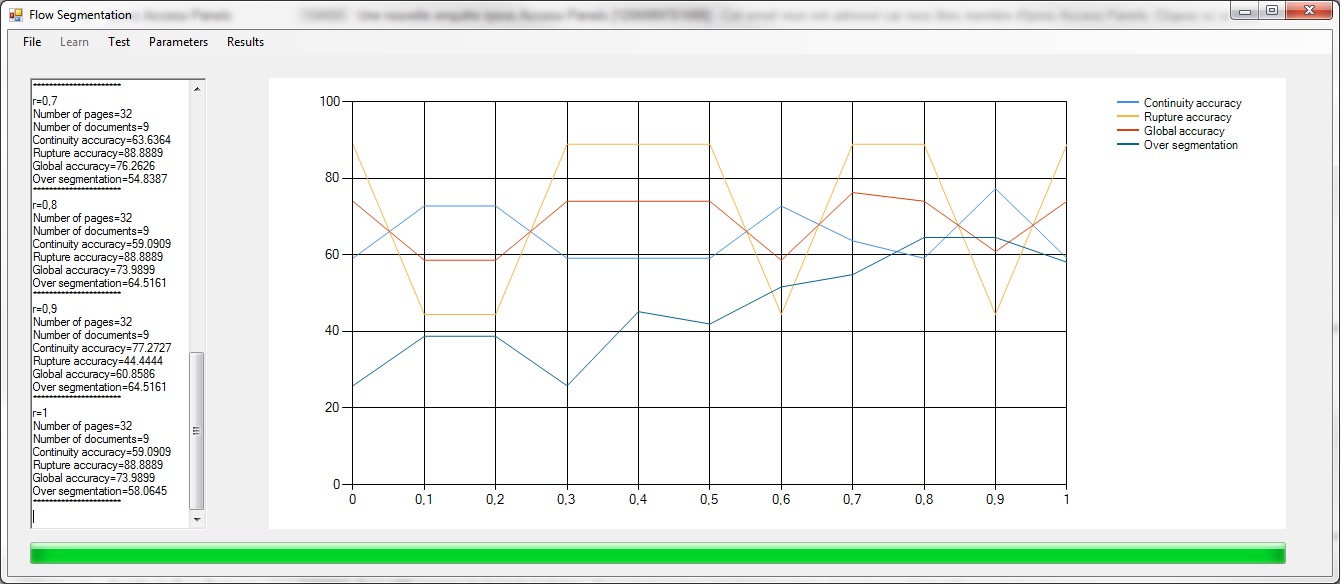 |
| Figure 2
Figure 2 illustrates continuity scores,rupture and over-segmentation for a given threshold. |
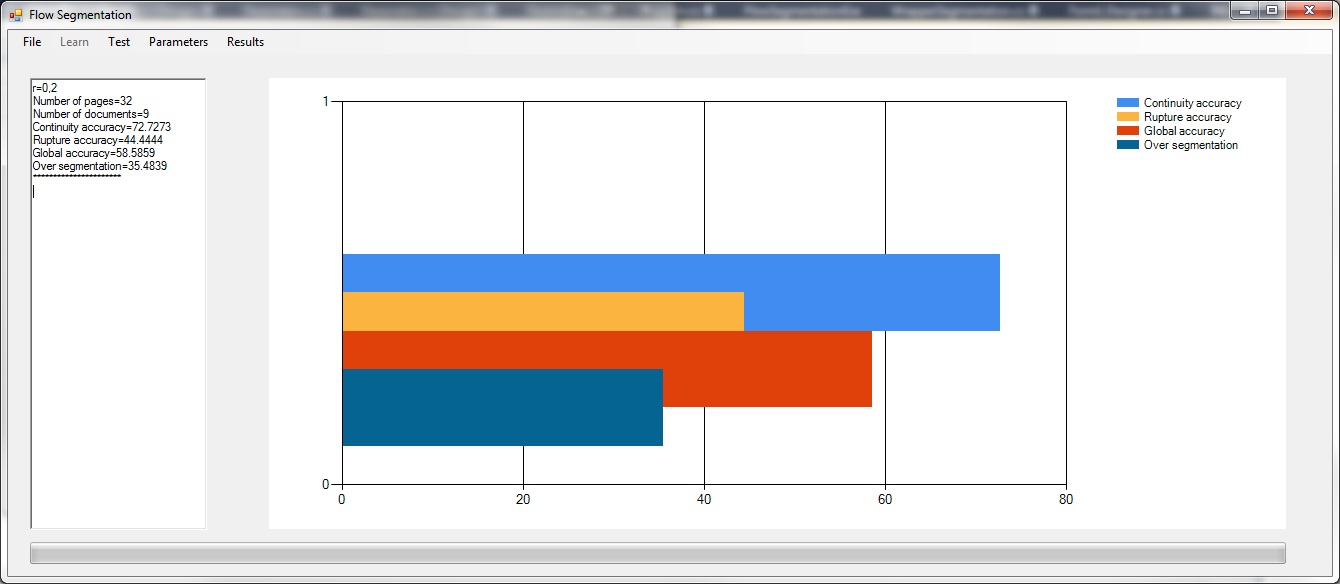 |
| Figure 3
Figure 3 illustrates the continuity case between two successive pages in the stream. On the right, the descriptors which value is equal to 1 are checked. |
 |
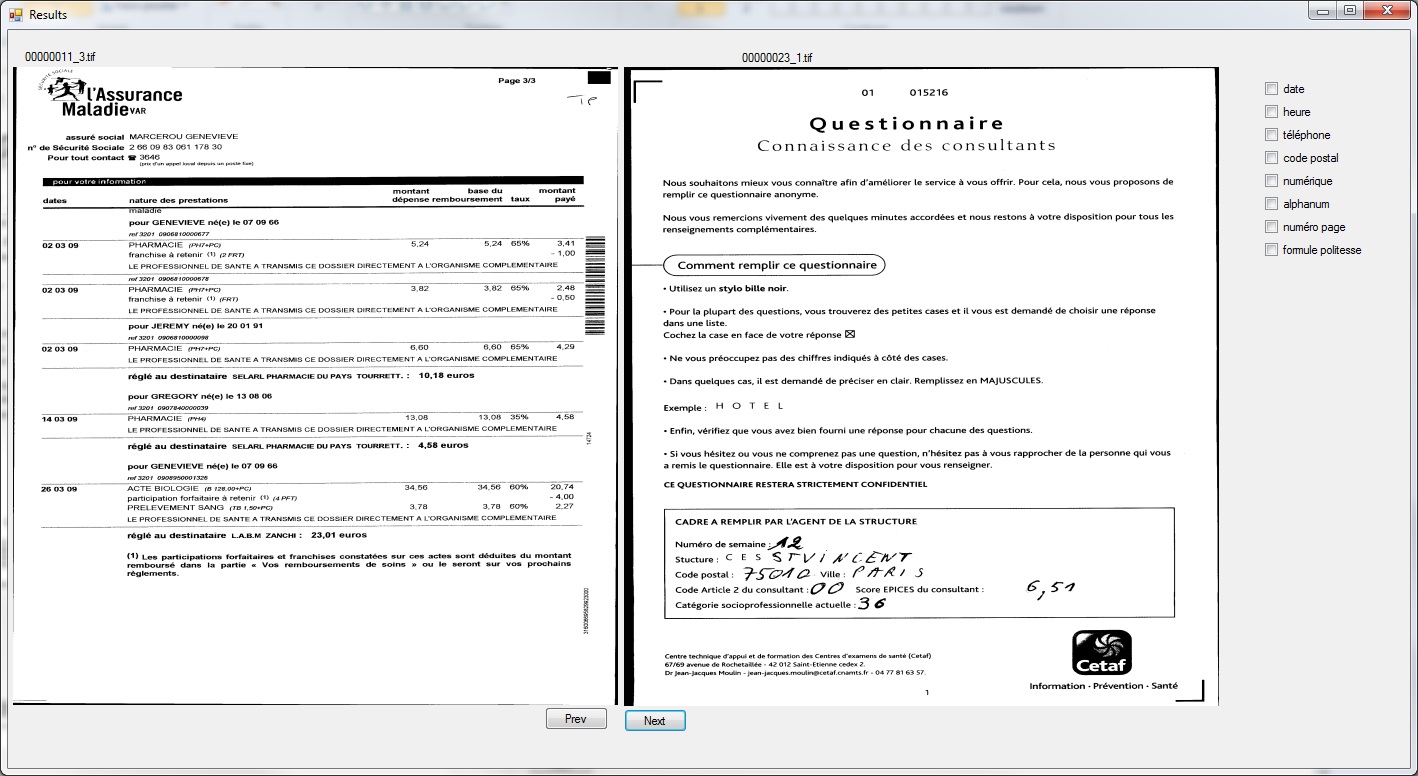
| Figure 4
The Figure 4 illustrate the confusion case. |
 |