|
|
|
|
|
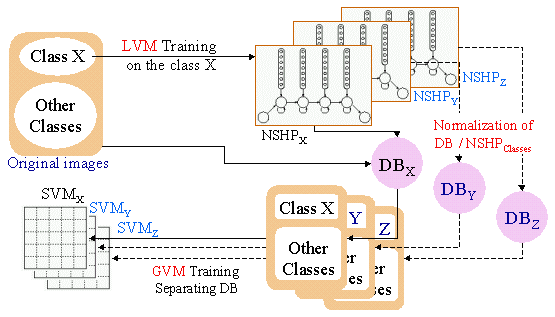
This work addresses the problem of the balance between global and local methods for handwriting recognition. This work constitutes one of the part of the PhD prepared by Christophe Choisy. In our approach, we combine Local View Method
(LVM) and Global View Method (GVM) for training. We use random fields as
LVM on each class of the DB. An LVM is trained on each class. Then, these
models are used to normalize all the DB samples. At this step, we
have got one normalized DB for each class. These normalized DB are used
as inputs for GVM models which are SVM.
|
 |
 |
|
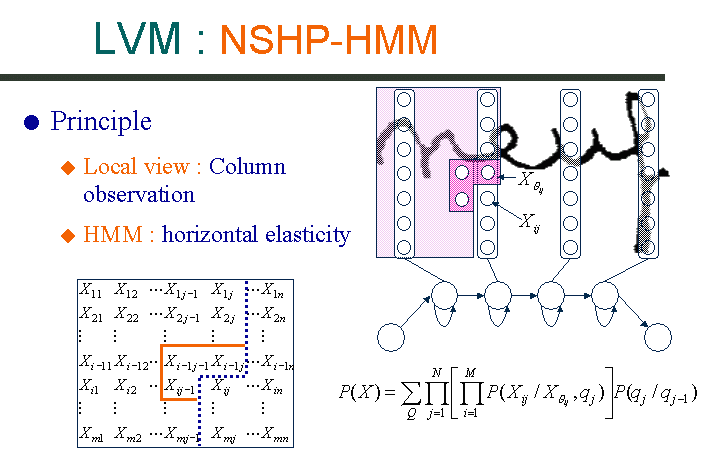
The LVM is a NSHP-HMM. It acts directly on the binary image by observing the columns in the HMM states. The local view corresponds to column observation. The HMM allows the observation repartition along the writing axis and this solves the length variation. The state observation probabilities are estimated by a Markov Random Field. A column probability is calculated as the product of the pixels probabilities. The pixel probability depends of a 2D neighborhood taken in the half plane yet analyzed. |
 |
|
The NSHP training is based on an analytic approach by cross learning : First, Word model is generated by linking letter models. Then these models are trained on their corresponding classes. At last, the information so obtained are synthesized in the letter models. Here we can see an illustration of this principle on the letter i in three word contexts. |
 |
|
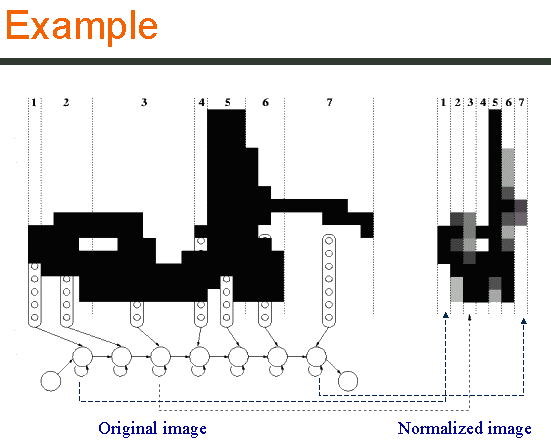
The objective is to obtain a normalized DB where each sample would have the same dimension according to the model of each class. The normalization method is based on the NSHP-HMM. The Viterbi algorithm gives the best state sequence to describe the input pattern at each state of the NSHP-HMM corresponds a column in the normalized image. The value of a normalized column is the mean value of the columns observed by the corresponding state in the sample. |
 |
|
Here, we illustrate the normalization principle on the word et by the model of its class. We can observe that the general shape is preserved. The horizontal bar of the t is compressed in only one column that is sufficient to keep the information. In the opposite, the cavity which is in general difficult to preserve is closed. But the cavity location is brightly. |
 |
|
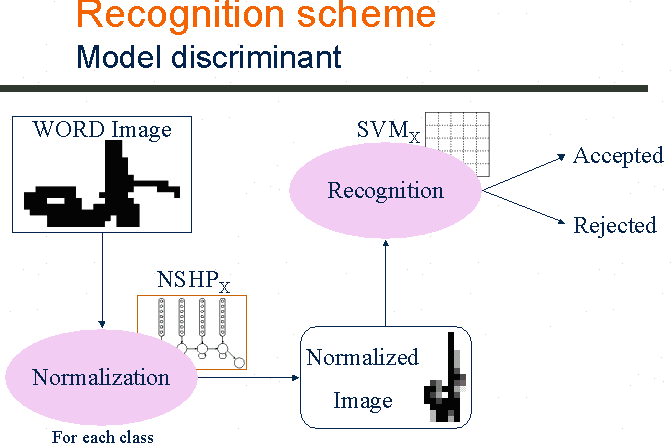
The recognition scheme is model discriminant. Given an input image to recognize, this image is first normalized by using a NSHP of each class. Then, the SVM of each class is applied of each one of the normalized samples to decide for the recognition. The belonging decision is taken by the SVM corresponding to each class. For the final decision, we have used three different method based on the SVM output value. |
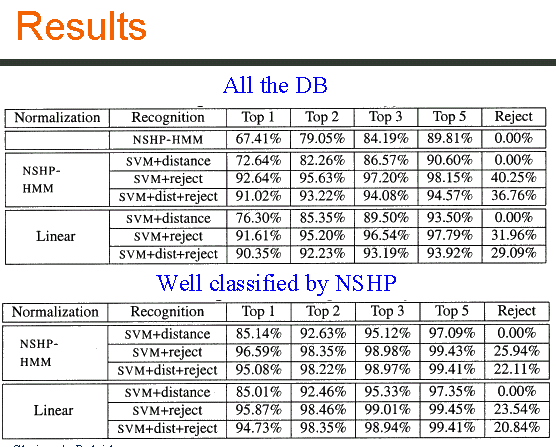 |
|
These tables show the recognition accuracies. We can observe in the first line of the first table that NSHP used used in the same condition as SVM, for recognition provides a low accuracy . Comparing linear and NSHP normalization, we can globally observe that NSHP is a lit bit better than linear but with more rejection. To evaluate the impact of NSHP normalization we made a second experiment considering only the well classified word by NSHP. We hoped that the words recognized by NSHP could be better normalized. In practice, the scores are improved and the rejection rate is strongly decreasing. It shows that improving the NSHP normalisation will improve the global results. |