|
|
| This software is designed by KC Santosh and improved by Tapan Bhowmik between January 2014 and August 2014. The goal of the project is to extract content within tables in document images based on learnt patterns. Clients provide a set of key fields in the form of client pattern within the tables which they think are relevant. The extraction will be based on the search for similar patterns. |
|
|
|
The client pattern is represented with a graph by:
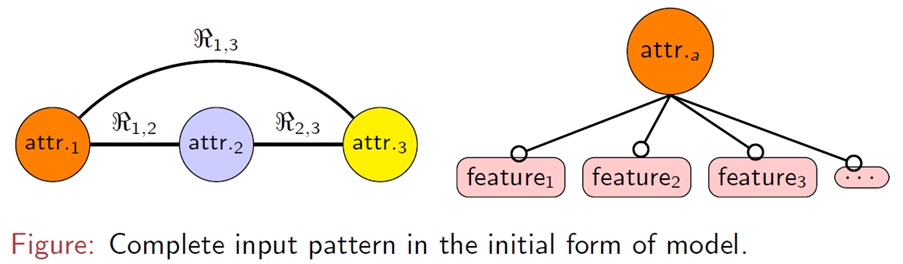 Here is a generated graph 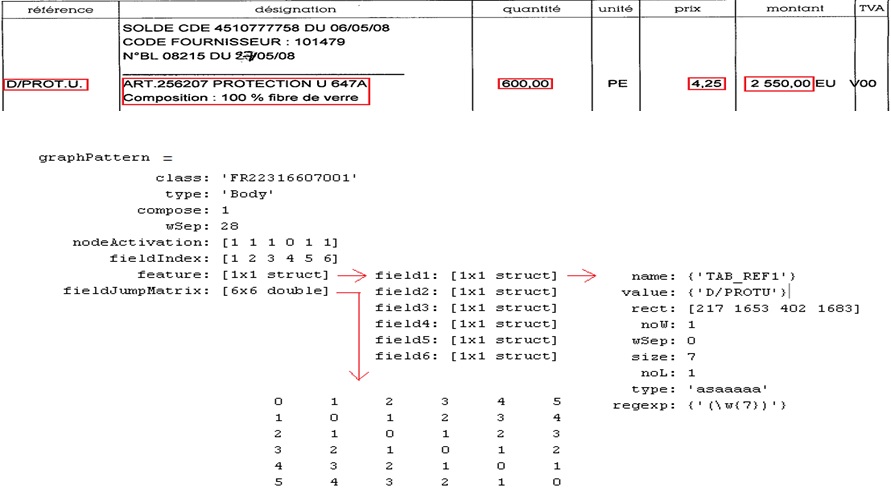 |
|
|
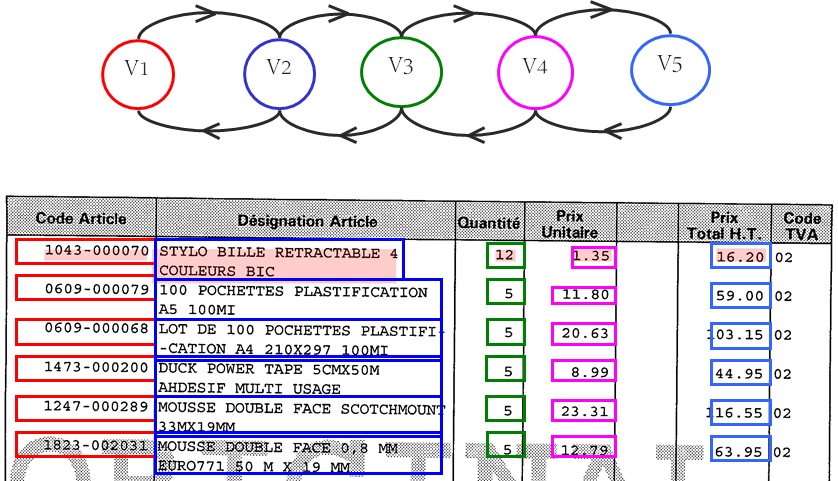
Graph mining in presence of client (Major Steps)
 |