|
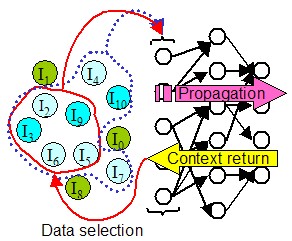
Project Osé-ITESOFT: Document on Demand
|
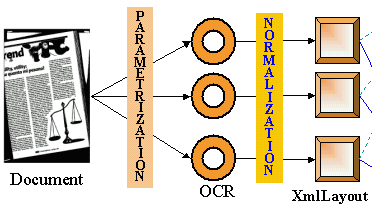
There are now a range of products to dematerialize (scan, identify and read automatically) paper documents
(letters, forms, invoices, checks, ...), but these solutions are currently only available for large companies.
DOD project is based on a new vision: the dematerialization for all.
It is developing a new generation of technologies to build software and web services product (SaaS) can handle
automatically after a simple learning by example, all paper and electronic documents that arrive daily in PMEs,
TPEs and homes.
The team READ takes part in the development of such products. About five are studied, concerning the flow segmentation,
incremental classification, heterogeneous document segmentation and information extraction.
|
|
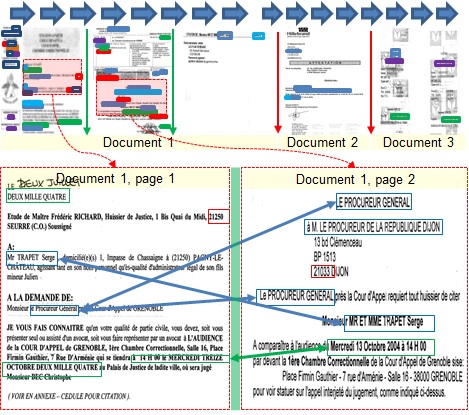
Document Stream Segmentation
-
Hani Daher proposes a framework for the segmentation and classification of multipage administrative document streams.
It is based on the careful search of textual descriptors and their neighborhood to model the limits between pages.
An incremental classifier is used to accommodate new classes of documents that may appear in the stream without
the need for a fixed training set. Lastly a semi-automatic cased based reasoning framework allows the system to
learn from the previous mistakes and correct potential future errors.
|

|
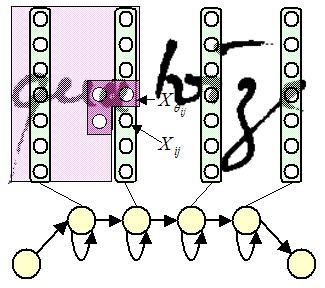
Printed/Handwritten Text Separation
-
Here we tackle the problem of machine
printed and handwritten text separation in real noisy documents.
A first version of the system was proposed by Didier Grzejszczak. Pseudo-lines and pseudo-words are used as basic blocks
for classification. Then, the local neighborhood of each pseudo-word
is studied in order to propagate the context and correct the
classification errors. Montaser Awal extends this
separation problem by conditional random fields considering the
horizontal neighborhood. He than enhanced this method
by using a more global context based on class dominance in the
pseudo-line.
|
|
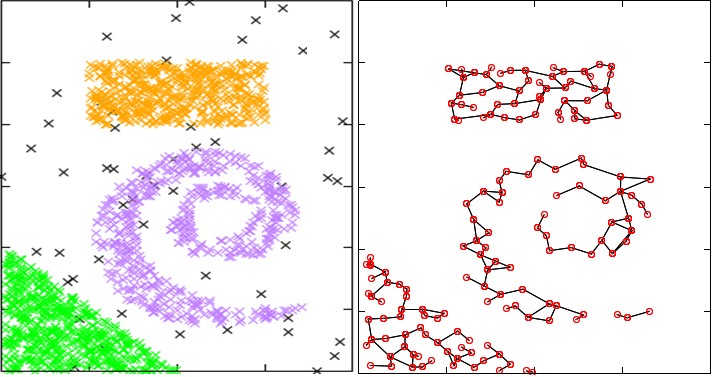
Incremental Clustering
-
Based on an adaptive incremental neural
gas algorithm (AING), Rafik Bouguélia proposes a new stream-based semisupervised
active learning method (A2ING) for document classification,
which is able to actively query (from a human annotator)
the class-labels of documents that are most informative for learning,
according to an uncertainty measure. The method maintains
a model as a dynamically evolving graph topology of labelled
document-representatives that we call neurons. Experiments on
different real-world datasets show that the proposed method
requires on average only 36.3% of the incoming documents to be
labelled, for learning a model which achieves an average gain of
2.15-3.22% in precision, compared to the traditional supervised
learning with fully labelled training documents.
|
|
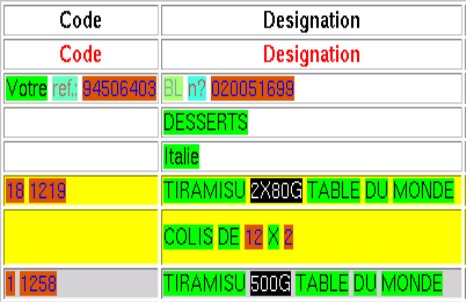
Table Extraction
-
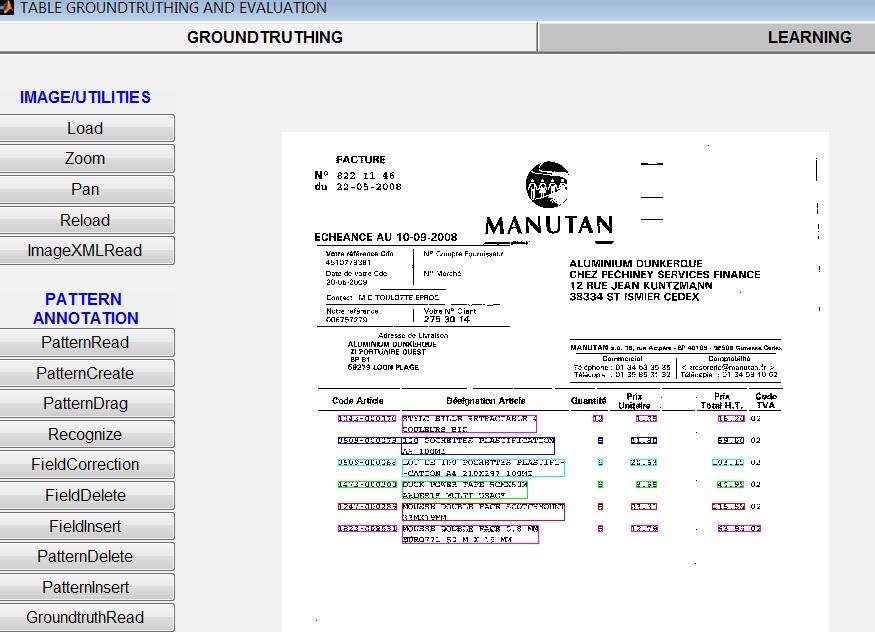
Thotreingam Kasar is involved in the development of an interactive tool for testing and evaluating a
query-based table information extraction system, developed at our laboratory. The interface is also
being used for generating table groundtruth and performance evaluation.
- Tapan Bhowmik is working on the development of a system for Table
information retrieval. The objective of this work is to retrieve similar patterns from
the document on the basis of an input query pattern defined by a client. A graph
searching technique is used to retrieve the similar patterns from the document.
|

|
Entity matching in documents with structured database
-
Nihel Kooli proposes an approach of entity recognition in documents recognized by OCR based on entity
resolution in industrial databases. A pre-step of entity resolution provides a non-redundant database. Then,
an adapted method is used to retrieve the entities from their structures that tolerates possible OCR errors. Nihel
applied an adapted version of EROCS (Chakaravarthy et al., 2006), which operates on document segments to match the
document to its corresponding entities. The segments correspond to elementary blocks given by the OCR.
|
|
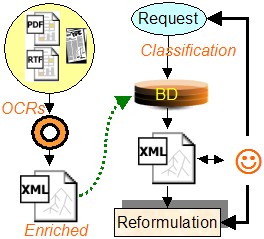
Project ECLEIR-eNovalys - Cifre
|
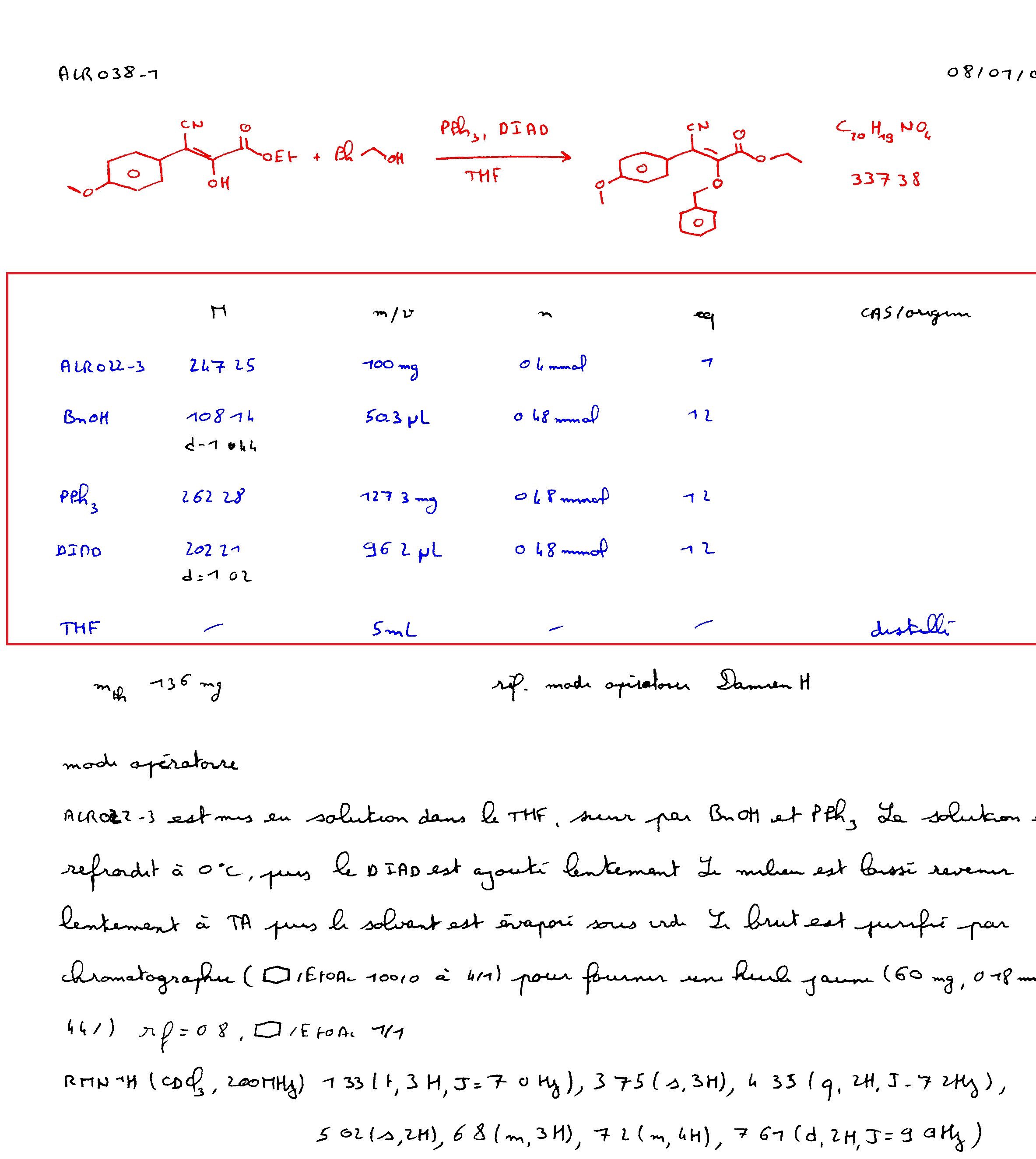
Under the ECLEIR project, in collaboration with the company eNovadys (Strasbourg) we seek to develop an aid
to the collection of chemical data to provide the community a specific database. The work involves digitizing
heritage knowledge contained in chemist laboratory notebooks to give them access. These data are very well
structured in a sequence always the same and which contains a reaction scheme, a table, several paragraphs of
text and some images. It is a document that is produced in handwritten and is therefore difficult to operate digitally.
One of the challenges of the project is therefore to develop tools to simplify the passage of such manuscripts to electronic documents.
|
|
Document Segmentation
-
Nabil Ghanmi addresses the problem of segmentation of chemistry documents in homogeneous
areas such as the chemical formula, the table and the text lines. After noise filtering, elementary structures such as lines and
parts of words are extracted. Specific descriptors taking into account the texture of the text and graphics are considered.Then,
the document elementary are classified in one of three classes. For table separation, Nabil Ghanmi uses a labeling task based on a
CRF model. It combines two classifiers: a local classifier which assigns a label to the line based on local features and a
contextual classifier which uses features taking into account the neighbourhood. The
CRF model gives the global conditional probability of a given
labeling of the line considering the results of the two classifiers.
|